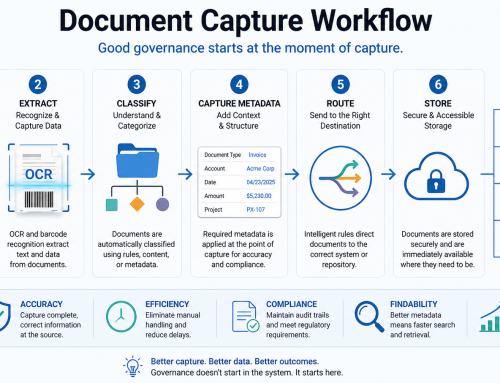
What is OCR and where did it come from?
One of the fundamental building blocks of ccScan is using OCR or Optical Character recognition. OCR is the computer language the scrapes the text from a document so it can be used for various tasks such as naming a file or doing a lookup in the cloud. This is how ccScan can save a user so much time not needing to do those tasks manually.
OCR is the electronic translation of scanned images of machine-printed text into machine-encoded text. It’s used to convert books and documents into electronic files or to publish text on a website. OCR makes it possible to edit the text, search for a word or phrase, store it more compactly, and display or print a copy. Based on the analysis of sequential lines and curves, OCR makes “best guesses” at characters using database look-up tables to closely associate or match the strings of characters that form words.
The basis of OCR technology was originally patented out of Germany in the 1920s, but it was not until 1950 that David H Shepard, a former cryptanalyst from US military, delivered the world’s first commercial OCR system. In the 1960s, Reader’s Digest built an OCR document reader to digitize serial numbers from coupons returned from print advertisements. By 1974, Ray Kurzweil developed the first omni-font OCR system – a computer program capable of recognizing text in any standard font, initially designed as a reading machine for the visually impaired. With Kurzweil’s application, the computer ingests printed content and it reads the text aloud to its audience. The technology went mainstream and was sold to Xerox in 1980 who further commercialized paper to text conversion.
Today OCR is used in many different industries including Document Management Applications, passport recognition, ID verification, assistive technology market for blind and visually impaired users, even monitoring video feeds, and of course ccScan.